2.5D Acoustics
We introduce an extended lumped two-dimensional acoustic wave propagation model (2.5D acoustics) having acoustic characteristics comparable to a precise three-dimensional (3D) model. Unlike one- and two-dimensional models limited to radial symmetry, our lightweight 2.5D finite-difference time-domain (FDTD) wave solver handles irregular geometries bound only to mid-sagittal symmetry. We demonstrate the precision and computational efficiency of our proposed wave solver by modelling vocal tract acoustics.
Introduction
Speech production is a complex but unique physiological process which requires the neuromuscular and biomechanical control of the human vocal apparatus (e.g., lips, jaw, tongue, etc.). A possible path to explore the underlying speech production mechanism is to build an articulatory-acoustic model (i.e., a quantitative computer-implemented emulation of the human speech organs or biomechanical articulatory speech synthesizer - BASS) that can generate acoustic speech signals (Kroger, 2022). Designing such an articulatory-acoustic model as a single unit is highly complex. Hence, it can be modularized into three primary components based on their core functionality.
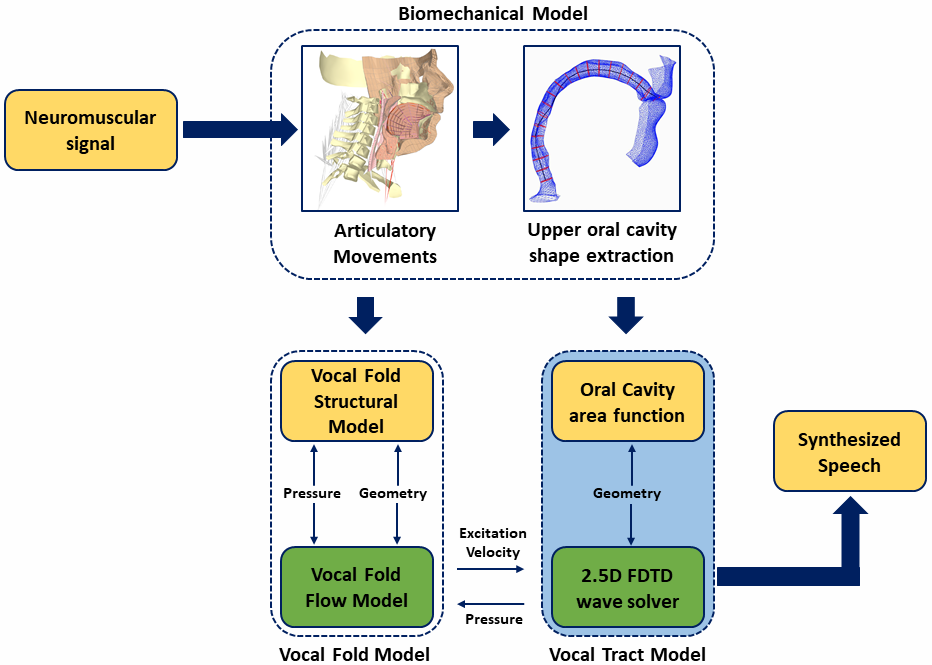
(1) A biomechanical model that generates articulatory kinematic movements from muscle activations and incorporates speech-related constraints.
(2) A vocal fold model that emulates the oscillatory movement of vocal cords in the larynx and generates glottal flow as the acoustic source.
(3) A vocal tract acoustic model that synthesizes speech sounds as per the vocal tract geometry (i.e., the shape of the upper oral cavity).
This project primarily focuses on vocal tract acoustic modelling.
Background
The vocal tract model comprises a numerical acoustic wave solver that simulates the acoustic wave propagation inside a given tube-like geometry. Faster simulations (i.e., real-time performance) can be achieved by restricting wave propagation to a single dimension (1D). However, the 1D wave solver assumes plane wave propagation inside the vocal tract geometry (i.e., acoustic pressure changes along the propagation direction) and only describes the appearance of fundamental modes. Hence, 1D models can produce a good match of formant locations (i.e., resonances) up to 5kHz. The only vocal tract geometries that 1D systems can directly simulate are straight cylindrical tubes with circular cross-sections. Alternatively, 3D models precisely approximate the geometrical complexity and acoustic characteristic of real vocal tracts at the expense of the computational run-time.
As a step forward from pure plane wave simulations, speech synthesis research has recently explored the usage of 2D acoustic models for pressure propagation, which provides a valuable trade-off between speed and quality. They are computationally faster than 3D models and can synthesize speech sounds resembling the natural voice. However, the existing 2D models have several limitations, as thoroughly discussed by Arnela and Guasch in the case of vowel synthesis. These models produce erroneous formant positions with the direct usage of the vocal tract's area functions extracted from MRIs. Moreover, these models still limit vocal tract geometries to straight tubes with circular cross-sections.
Synthesized Vowels
Vowel [a]
Vowel [i]
Vowel [u]